How Do Machine Learning Algorithms Work?
When drawing predictions, classifications, or taking actions, machine learning algorithms use data to identify patterns and relationships. The algorithm’s specific operations vary depending on its nature and the problem it attempts to answer. According to Nature, ML algorithms were used to predict the mortality of COVID-19 patients with 92% accuracy. Breast cancer can be identified with 99% accuracy by Google’s Deep Learning ML software.
Here’s the complete machine learning algorithms cheat sheet you need:
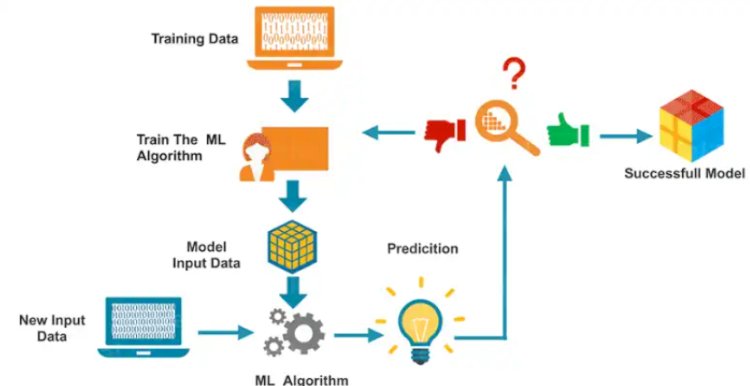
- Data Gathering: For the machine learning activity, relevant information is gathered and prepared. For supervised learning, these data may consist of features (input variables) and labels (output variables), or unlabeled data for unsupervised learning.
- Data Preprocessing: The gathered data is cleaned, converted, and preprocessed to guarantee its quality and compliance with the algorithm. This stage might involve deleting duplicates, dealing with missing values, scalability of features, or categorical variable encoding.
- Training Phase: In supervised learning, the algorithm learns to map the input features to the matching output labels by training on labeled data. Utilizing optimization techniques, the program modifies its internal parameters or model during training to reduce the discrepancy between expected and real labels.
- Evaluation: Post training, the algorithm is assessed using a different dataset known as the test set. This assessment gauges how well the algorithm performs and how well it can categorize or make predictions based on brand-new data.
- Model Deployment: If the algorithm performs satisfactorily, it can be applied to new, real-world data to make predictions or assign categories. This can entail incorporating the model into a program or system so that it can communicate with users or offer information.
- Iterative Improvement: ML algorithms can be improved regularly by adding more data, retraining the model, adjusting hyperparameters, or utilizing more complex methods like deep learning or ensemble learning.
It’s crucial to remember that various machine learning techniques, including decision trees, support vector machines, neural networks, and clustering algorithms, each have unique underlying principles and algorithms. Depending on the characteristics of the problem at hand and the data at hand, each algorithm has its advantages, disadvantages, and best uses.
Additionally, the suitability and representativeness of the training data, the selection of relevant features, and the careful choice of algorithmic parameters are all pivotal for the success of ML algorithms.
Winding Up
The way we tackle complicated problems and make predictions across a variety of fields has been completely transformed by machine learning algorithms. These algorithms are able to spot patterns, learn from data, and generate precise predictions or classifications. The performance of ML algorithms can be enhanced continuously through the iterative process of training, evaluating, and refining.
Many industries, such as healthcare, finance, marketing, and robotics, have effectively used ML algorithms. They have the ability to boost decision-making processes, automate procedures, and extract hidden insights from massive datasets. ML algorithms have the potential to revolutionize industries and enhance our daily lives by doing everything from forecasting the impact of diseases to making personalized product recommendations.
That being said, it’s crucial to understand that ML algorithms are not flawless. They are only as good as the training data and feature sets that they are fed. Predictions may be inaccurate or prejudiced if the training data contains biases or mistakes. Therefore, to guarantee the accuracy and fairness of machine learning algorithms, thorough data collection, preprocessing, and model validation are essential.





















